A Assimetria se refere à distribuição desigual dos dados em torno de uma média em uma distribuição de frequências, ou seja, ela representa a falta de correspondência ou equilíbrio entre suas partes, a falta de simetria. Logo abaixo, uma representação de uma distribuição simétrica.
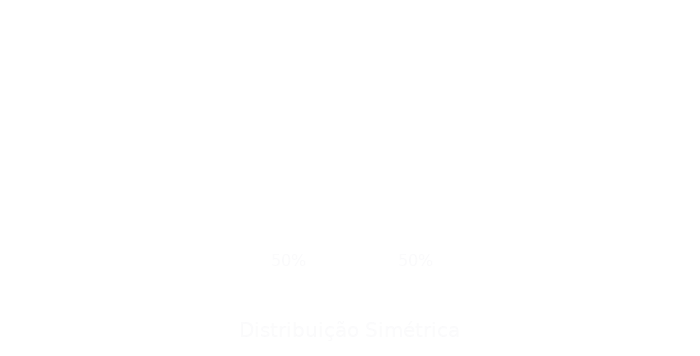
Segundo Martins e Domingues (2014, p. 49), “em uma distribuição simétrica, há igualdade dos valores da média, mediana e moda”. Mas se em uma distribuição de dados estatísticos não tivermos coincidência entre os valores da média aritmética, da mediana e da moda, teremos uma distribuição assimétrica, que pode ser:
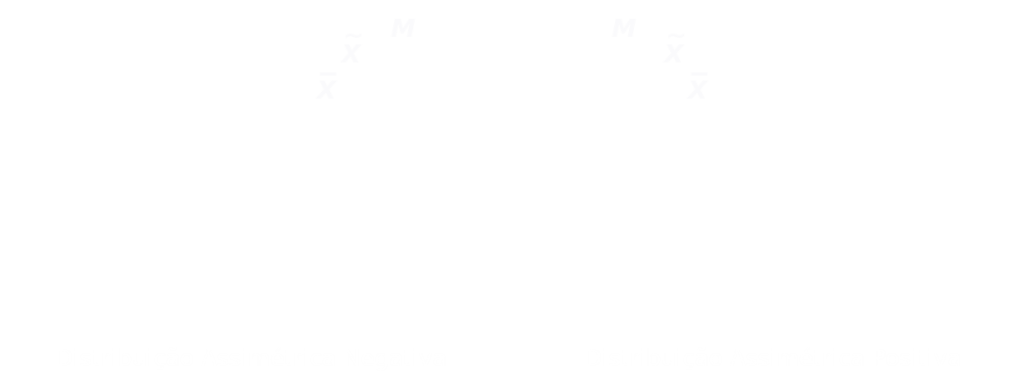
- Distribuição assimétrica negativa ou assimétrica à esquerda:
$$\large \begin{matrix} M > \tilde{x} > \bar{x}\\ \small ou\\ \normalsize M > \tilde{x} > \mu \end{matrix}$$
- Distribuição assimétrica positiva ou assimétrica à direita:
$$\large \begin{matrix} M < \tilde{x} < \bar{x}\\ \small ou\\ \normalsize M < \tilde{x} < \mu \end{matrix}$$
Para que seja possível determinar o grau de assimetria de uma distribuição de dados, os cálculos mais comumente utilizados são os que fornecem o primeiro e o segundo coeficientes de Pearson.
Fórmulas de Assimetria de Pearson:
1º coeficiente – Utiliza a Moda (M)
$$\normalsize Amostras: \large AS_{P1} = \frac{\bar{x} – M}{s}$$
$$\normalsize Populações: \large AS_{P1} = \frac{\mu – M}{\sigma}$$
2º coeficiente – Utiliza a Mediana ($\color{orangered} \tilde{x}$ ou Med)
$$\normalsize Amostras: \large AS_{P2} = \frac{3 \cdot (\bar{x} – \tilde{x})}{s}$$
$$\normalsize Populações: \large AS_{P2} = \frac{3 \cdot (\mu – \tilde{x})}{\sigma}$$
Sendo:
- $\bar{x}$: média aritmética amostral
- $\mu$: média aritmética populacional
- $s$: desvio padrão amostral
- $\sigma$: desvio padrão populacional
- $\tilde{x}$: mediana amostral ou populacional
- $M$: moda amostral ou populacional
Python :
' 1º coeficiente '
# Descobrindo o valor da média ponderada
m = sum(list(map(lambda x, y: (x*y), valor, freq))) / sum(freq)
# Descobrindo o valor da moda
Moda = list(valor)[freq.index(max(freq))]
# Descobrindo o valor do desvio padrão
s = sum(list(map(lambda x, y: (((x - m)**2)*y) / (sum(freq)), valor, freq)))**0.5
# Calculando o 1º coeficiente de assimetria
Asp1 = (m - Moda) / s' 2º coeficiente '
# Descobrindo o valor da média ponderada
m = sum(list(map(lambda x, y: (x*y), valor, freq))) / sum(freq)
# Descobrindo o valor da mediana
Med = sorted([x for x, f in dicio.items() for i in range(f)])[sum(dicio.values()) // 2]
# Descobrindo o valor do desvio padrão
s = sum(list(map(lambda x, y: (((x - m)**2)*y) / (sum(freq)), valor, freq)))**0.5
# Calculando o 2º coeficiente de assimetria
Asp2 = 3*(m - Med) / sJulia :
" 1º coeficiente "
# Descobrindo o valor da média ponderada
m = sum(valor .* freq) / sum(freq)
# Descobrindo o valor da moda
Moda = valor[argmax(freq)]
# Descobrindo o valor do desvio padrão
s = sum(((valor .- m).^2) .* freq / sum(freq))^0.5
# Calculando o 1º coeficiente de assimetria
Asp1 = (m - Moda) / s" 2º coeficiente "
# Descobrindo o valor da média ponderada
m = sum(valor .* freq) / sum(freq)
# Descobrindo o valor da mediana
Med = sort([x for (x, y) in zip(valor, freq) for i in 1:y])[floor(Int64, (sum(freq)/2))]
# Descobrindo o valor do desvio padrão
s = sum(((valor .- m).^2) .* freq / sum(freq))^0.5
# Calculando o 2º coeficiente de assimetria
Asp2 = 3 * (m - Med) / sAtenção!
O primeiro coeficiente de assimetria de Pearson utiliza a moda. Se, em um conjunto de dados, a moda é definida por poucas unidades, ela não é uma boa medida de tendência central e não deve ser usada para calcular assimetria.
Por exemplo: No conjunto de dados {1, 2, 3, 4, 5, 5} a moda não expressa bem a tendência central. Já no conjunto {1, 2, 3, 3, 3, 3, 3, 3, 4} a moda expressa a tendência central.
Por isso, o segundo coeficiente deve preferencialmente ser usado no cálculo.
Dados agrupados SEM intervalos de classe
Python
dicio = {5:1, 6:7, 7:10, 8:10, 9:2, 10:2, 11:1}
# Criando duas listas contendo os valores e frequências
valor = list(dicio.keys())
freq = list(dicio.values())
m = sum(list(map(lambda x, y: (x*y), valor, freq))) / sum(freq)
Moda = list(valor)[freq.index(max(freq))]
Med = sorted([x for x, f in dicio.items() for i in range(f)])[sum(dicio.values()) // 2]
s = sum(list(map(lambda x, y: (((x - m)**2)*y) / (sum(freq)), valor, freq)))**0.5
prim = (m - Moda) / s
seg = 3*(m - Med) / s
print(f'Asp1 = {prim} / Asp2 = {seg}')Julia
dicionario = Dict(5=>1, 6=>7, 7=>10, 8=>10, 9=>2, 10=>2, 11=>1)
# Criando duas listas contendo os valores e frequências
valor = collect(keys(dicionario))
freq = collect(values(dicionario))
m = sum(valor .* freq) / sum(freq)
Moda = [k for (k, v) in dicionario if v == maximum(freq)][1]
Med = sort([x for (x, y) in zip(valor, freq) for i in 1:y])[floor(Int64, (sum(freq)/2))]
s = sum(((valor .- m).^2) .* freq / sum(freq))^0.5
Asp1 = (m - Moda) / s
Asp2 = 3 * (m - Med) / sDados agrupados COM intervalos de classe
Python
'''Calculando a assimetria de uma série de dados COM intervalos de classe'''
dicio ={'59.0 - 61.5':3,'61.5 - 64.0':5,'64.0 - 66.5':5,'66.5 - 69.0':7,
'69.0 - 71.5':9,'71.5 - 74.0':11,'74.0 - 76.5':8,'76.5 - 79.0':7,
'79.0 - 81.5':5,'81.5 - 84.0':6,'84.0 - 86.5':4}
valor = list(map(lambda x: (float(x.split(' - ')[0]) + float(x.split(' - ')[1])) / 2, list(dicio.keys())))
freq = list(dicio.values())
dicionario = dict(zip(valor, freq))
# Descobrindo o valor da média
m = sum(list(map(lambda x, y: (x*y), valor, freq))) / sum(freq)
# Descobrindo o valor da moda
Moda = list(valor)[freq.index(max(freq))]
# Descobrindo o valor da mediana
Med = sorted([x for x, f in dicionario.items() for i in range(f)])[sum(dicionario.values()) // 2]
# Descobrindo o valor do desvio padrão
s = sum(list(map(lambda x, y: (((x - m)**2)*y) / (sum(freq)), valor, freq)))**0.5
prim = (m - Moda) / s
seg = 3*(m - Med) / s
print(f'Asp1 = {prim} / Asp2 = {seg}')Julia
" Calculando a assimetria de uma série de dados COM intervalos de classe "
dicio = Dict("59.0 - 61.5"=>3,"61.5 - 64.0"=>5,"64.0 - 66.5"=>5,"66.5 - 69.0"=>7,"69.0 - 71.5"=>9,"71.5 - 74.0"=>11, "74.0 - 76.5"=>8,"76.5 - 79.0"=>7,"79.0 - 81.5"=>5,"81.5 - 84.0"=>6,"84.0 - 86.5"=>4)
# Ordenando os valores pela ordem do dicionario
dicio = sort(collect(dicio))
# valores médio de cada intervalo de classe
valor = map(x -> (parse(Float64, split(x[1], " - ")[1]) + parse(Float64, split(x[1], " - ")[2]))/2, dicio)
# frequência de cada intervalo de classe
freq = [par.second for par in dicio]
# Descobrindo o valor da média
m = sum(valor .* freq) / sum(freq)
# Descobrindo o valor da moda
Moda = valor[argmax(freq)]
# Descobrindo o valor da mediana
Med = sort([x for (x, y) in zip(valor, freq) for i in 1:y])[floor(Int64, (sum(freq)/2))]
# Descobrindo o valor do desvio padrão
s = s = sum((valor .-m).^2 .* freq / sum(freq))^0.5
prim = (m - Moda) / s
seg = 3*(m - Med) / s
println("Asp1 = $prim / Asp2 = $segn")Outro exemplo
" Calculando a assimetria de uma série de dados COM intervalos de classe, usando DataStructures "
using DataStructures
dicio = OrderedDict("59.0 - 61.5"=>3,"61.5 - 64.0"=>5,"64.0 - 66.5"=>5,"66.5 - 69.0"=>7,"69.0 - 71.5"=>9,"71.5 - 74.0"=>11, "74.0 - 76.5"=>8,"76.5 - 79.0"=>7,"79.0 - 81.5"=>5,"81.5 - 84.0"=>6,"84.0 - 86.5"=>4)
# valores médio de cada intervalo de classe
valor = map(x -> (parse(Float64, split(x, " - ")[1]) + parse(Float64, split(x, " - ")[2])) / 2, collect(keys(dicio)))
# frequência de cada intervalo de classe
freq = collect(values(dicio))
# Descobrindo o valor da média
m = sum(valor .* freq) / sum(freq)
# Descobrindo o valor da moda
Moda = valor[argmax(freq)]
# Descobrindo o valor da mediana
Med = sort([x for (x, y) in zip(valor, freq) for i in 1:y])[floor(Int64, (sum(freq)/2))]
# Descobrindo o valor do desvio padrão
s = s = sum((valor .-m).^2 .* freq / sum(freq))^0.5
prim = (m - Moda) / s
seg = 3*(m - Med) / s
println("Asp1 = $prim / Asp2 = $segn")
# RESPOSTA: Asp1 = 0.04221297937335779 / Asp2 = 0.12663893812007337Dependendo do resultado do cálculo, classificamos a distribuição de dados conforme o estabelecido a seguir:
| Classificação | Descrição |
|---|---|
| AS = 0 | Distribuição simétrica |
| 0 < As < 1 | Distribuição assimétrica positiva fraca |
| As ≥ 1 | Distribuição assimétrica positiva forte |
| -1 < As < 0 | Distribuição assimétrica negativa fraca |
| As ≤ -1 | Distribuição assimétrica negativa forte |
Importante !
Quando não pudermos determinar o valor do desvio padrão, seja ele amostral ou populacional, não utilizaremos os coeficientes de Pearson para indicar o grau de assimetria dos dados.
Existem outras formas de se calcular o grau de assimetria. Uma alternativa é usarmos o cálculo do Coeficiente Quartílico de Assimetria (CQA) ou Fórmula de Bowley, que é:
Fórmula do Coeficiente Quartílico de Assimetria de Bowley:
$$\begin{matrix} CQA = \dfrac{Q_{3}-2 \cdot Q_{2}+Q_{1}}{Q_{3}-Q_{1}}\\ ou\\ CQA = \dfrac{(Q_{3}-Q_{2})-(Q_{2}-Q_{1})}{Q_{3}-Q_{1}} \end{matrix}$$
Sendo:
- Q1: 1º quartil
- Q2: 2º quartil
- Q3: 3º quartil
Python / Julia :
CQA = (Q3-2*Q2+Q1) / (Q3-Q1)Esta fórmula é mais sensível a valores extremos do que outras medidas de assimetria.
Python
# Calculando a assimetria de uma série de dados SEM intervalos de classe
dicio = {5:1, 6:7, 7:10, 8:10, 9:2, 10:2, 11:1}
# total da frequência
N = sum(list(dicio.values()))
# Frequência acumulada
fa = list(map(lambda x: sum(list(dicio.values())[:x + 1]), range(len(list(dicio.values())))))
lista = []
for n in [1,2,3]:
pn = (n * (N + 1)) / 4
if pn % 2 != 0:
PD = pn - int(pn)
trunc = int(pn)
else:
PD = 0
trunc = pn
posit_1 = list(filter(lambda x: x >= trunc, fa))[0]
posit_2 = list(filter(lambda x: x >= trunc+1, fa))[0]
VP = list(dicio.keys())[fa.index(posit_1)]
VP1 = list(dicio.keys())[fa.index(posit_2)]
Q = VP + PD * (VP1 - VP)
lista.append(Q)
Q1 = lista[0]
Q2 = lista[1]
Q3 = lista[2]
CQA = (Q3-2*Q2+Q1) / (Q3-Q1)
print(CQA)# Calculando a assimetria de uma série de dados COM intervalos de classe
dicionario ={'59.0 - 61.5':3,'61.5 - 64.0':5,'64.0 - 66.5':5,'66.5 - 69.0':7,
'69.0 - 71.5':9,'71.5 - 74.0':11,'74.0 - 76.5':8,'76.5 - 79.0':7,
'79.0 - 81.5':5,'81.5 - 84.0':6,'84.0 - 86.5':4}
lista = list(dicionario.values())
fa = list(map(lambda x: sum(lista[:x+1]), range(len(lista))))
val = []
for n in [1,2,3]:
pn = (n * sum(list(dicionario.values()))) / 4
num = list(filter(lambda x: x >= pn, fa))[0]
interval = list(dicionario.keys())[fa.index(list(filter(lambda x: x == num, fa))[0])]
li = float(interval.split(' - ')[0])
h = float(interval.split(' - ')[1]) - float(interval.split(' - ')[0])
m = list(filter(lambda x: x < pn, fa))[-1]
fm = dicionario.get(interval)
Q = li + ((h * (pn - m))/fm)
val.append(Q)
Q1 = val[0]
Q2 = val[1]
Q3 = val[2]
CQA = (Q3-2*Q2+Q1) / (Q3-Q1)
print(CQA)
Julia
# Calculando a assimetria de uma série de dados SEM intervalos de classe
dicio = Dict(5=>1, 6=>7, 7=>10, 8=>10, 9=>2, 10=>2, 11=>1)
# Corrigindo a ordem das frequências de um dicionário e salvando uma variável
indices_e_valores = collect(enumerate(dicio))
indices_e_valores_ordenados = sort(indices_e_valores, by=x -> x[2])
indices = [indice for (indice, valor) in indices_e_valores_ordenados]
valor = map(y -> collect(keys(dicio))[y], indices)
freq = map(y -> collect(values(dicio))[y], indices)
# Frequência acumulada
fa = cumsum(freq)
# total da frequência
N = sum(freq)
valores = []
for n in [1,2,3]
pn = n * (N + 1) / 4
PD = pn % 2 != 0 ? pn - floor(Int64, pn) : 0
trunc = pn % 2 != 0 ? floor(Int64, pn) : pn
posit_1 = fa[findfirst(x -> x == 1, fa .>= trunc)]
posit_2 = fa[findfirst(x -> x == 1, fa .>= trunc+1)]
VP = valor[findfirst(x -> x == posit_1, fa)]
VP1 = valor[findfirst(x -> x == posit_2, fa)]
Q = VP + PD * (VP1 - VP)
push!(valores, Q)
end
Q1 = valores[1]
Q2 = valores[2]
Q3 = valores[3]
CQA = (Q3-2*Q2+Q1) / (Q3-Q1)Fórmula do Coeficiente de assimetria de Pearson ou O momento de terceira ordem padronizado:
$$\large As = \dfrac{\sum(x_{i}-\bar{x})^3}{(n-1) \cdot s^3}$$
Sendo:
- $x_{i}$: Representa cada valor individual em seu conjunto de dados.
- $\bar{x}$: A média aritmética dos valores do conjunto de dados.
- $\sum(x_{i} – \bar{x})^3$: A soma de todas as diferenças elevadas ao cubo para cada $x_{i}$.
- $n$: O número total de observações no conjunto de dados.
- $s$: O desvio padrão da amostra, que é a medida da dispersão dos dados em torno da média.
- $(n-1)$: O número de graus de liberdade do conjunto de dados.
Python :
As = sum(list(map(lambda x: (x - m)**3, lista))) / ((n-1) * s**3)Julia :
As = sum(((valor .- m).^3) .* freq) / ((n-1) * s^3)Exemplos
Python
dicio = {5:1, 6:7, 7:10, 8:10, 9:2, 10:2, 11:1}
valor = list(dicio.keys())
freq = list(dicio.values())
m = sum(list(map(lambda x, y: (x*y), valor, freq))) / sum(freq)
n = sum(freq)
s = sum(list(map(lambda x, y: (((x - m)**2)*y) / (sum(freq)-1), valor, freq)))**0.5
As = sum(list(map(lambda x, y: ((x - m)**3)*y, valor, freq))) / ((n-1) * s**3)
print(As)Julia
valor = [5, 6, 7, 8, 9, 10, 11]
freq = [1, 7, 10, 10, 2, 2, 1]
n = sum(freq)
m = sum(valor .* freq) / n
s = (sum((valor .- m).^2 .* freq) / (n-1))^0.5
As = sum(((valor .- m).^3) .* freq) / ((n-1) * s^3)Fórmula do Coeficiente de assimetria de Fisher:
$$\large As = \dfrac{\dfrac{\sum_{i=1}^{n}(x_{i}-\bar{x})^3}{n}}{\Bigg(\dfrac{\sum_{i=1}^{n}(x_{i}-\bar{x})^2}{n-1}\Bigg)^{3/2}}$$
Sendo:
- $x_{i}$: Representa cada valor individual em seu conjunto de dados.
- $\bar{x}$: A média aritmética dos valores do conjunto de dados.
- $\sum(x_{i} – \bar{x})^3$: A soma de todas as diferenças elevadas ao cubo para cada $x_{i}$.
- $n$: O número total de observações no conjunto de dados.
- $s$: O desvio padrão da amostra, que é a medida da dispersão dos dados em torno da média.
- $(n-1)$: O número de graus de liberdade do conjunto de dados.
Python :
As = (sum(list(map(lambda x: (x-m)**3, lista))) / n) / (sum(list(map(lambda x: (x-m)**2, lista))) / (n-1))**(3/2)Julia :
As = (sum(((valor .- m).^3) .* freq) / n) / (sum(((valor .- m).^2) .* freq) / (n-1))^(3/2)Exemplo
Python
dicio = {5:1, 6:7, 7:10, 8:10, 9:2, 10:2, 11:1}
valor = list(dicio.keys())
freq = list(dicio.values())
m = sum(list(map(lambda x, y: (x*y), valor, freq))) / sum(freq)
n = sum(freq)
s = sum(list(map(lambda x, y: (((x - m)**2)*y) / (sum(freq)), valor, freq)))**0.5
As = (sum(list(map(lambda x, y: ((x-m)**3)*y, valor, freq))) / n) / (sum(list(map(lambda x, y: ((x-m)**2)*y, valor, freq))) / (n-1))**(3/2)
print(As)Julia
valor = [5, 6, 7, 8, 9, 10, 11]
freq = [1, 7, 10, 10, 2, 2, 1]
n = sum(freq)
m = sum(valor .* freq) / n
s = (sum((valor .- m).^2 .* freq) / (n-1))^0.5
As = (sum(((valor .- m).^3) .* freq) / n) / (sum(((valor .- m).^2) .* freq) / (n-1))^(3/2)Fórmula do Coeficiente de assimetria de Fisher-Pearson:
Fórmula que entrega um resultado semelhante à função skew da biblioteca Scipy, no Python, e à função skewness da biblioteca StatsBase, em Julia.
$$\begin{matrix} \large As = \frac{\frac{1}{n} \sum_{i=1}^{n}(x_{i} – \bar{x})^3}{\bigg(\sqrt{\frac{1}{n} \sum_{i=1}^{n}(x_{i} – \bar{x})^2}\bigg)^3} \\ \small ou\\ \large As = \frac{m_{3}}{(\sqrt{m_{2}})^3} \end{matrix}$$
Sendo:
- $x_{i}$: Representa cada valor individual em seu conjunto de dados.
- $\bar{x}$: A média aritmética dos valores do conjunto de dados.
- $n$: O número total de observações no conjunto de dados.
- $s$: O desvio padrão da amostra, que é a medida da dispersão dos dados em torno da média.
Python :
As = ((1/n) * (sum(list(map(lambda x: (x-m)**3, lista))))) / ((((1/n) *(sum(list(map(lambda x: (x-m)**2, lista)))))**0.5)**3)Julia :
As = (1/n) * (sum(((valor .- m).^3) .* freq)) / (((1/n) * (sum(((valor .- m).^2) .* freq)))^0.5)^3Libs:
Exemplos
Python
''' Utilizando somente o Python '''
dicio = {5:1, 6:7, 7:10, 8:10, 9:2, 10:2, 11:1}
valor = list(dicio.keys())
freq = list(dicio.values())
m = sum(list(map(lambda x, y: (x*y), valor, freq))) / sum(freq)
n = sum(freq)
As = ((1/n) * (sum(list(map(lambda x, y: ((x-m)**3)*y, valor, freq))))) / ((((1/n) *(sum(list(map(lambda x, y: ((x-m)**2)*y, valor, freq)))))**0.5)**3)
print(As)''' Utilizando a função Skew da Biblioteca Scipy '''
import scipy.stats as sc
dicio = {5:1, 6:7, 7:10, 8:10, 9:2, 10:2, 11:1}
lista = list(k for k, v in dicio.items() for _ in range(v))
As = sc.skew(lista)
print(As)Julia
valor = [5, 6, 7, 8, 9, 10, 11]
freq = [1, 7, 10, 10, 2, 2, 1]
n = sum(freq)
m = sum(valor .* freq) / n
s = (sum((valor .- m).^2 .* freq) / (n-1))^0.5
As = (1/n) * (sum(((valor .- m).^3) .* freq)) / (((1/n) * (sum(((valor .- m).^2) .* freq)))^0.5)^3Fórmula do Coeficiente padronizado de assimetria de Fisher-Pearson:
$$As = \frac{n}{(n-1)(n-2)} \sum \bigg(\frac{x_{i}-\bar{x}}{s}\bigg)^3$$
Sendo:
- $x_{i}$: Representa cada valor individual em seu conjunto de dados.
- $\bar{x}$: A média aritmética dos valores do conjunto de dados.
- $n$: O número total de observações no conjunto de dados.
- $s$: O desvio padrão da amostra, que é a medida da dispersão dos dados em torno da média.
Python :
As = (n / ((n-1)*(n-2))) * sum(list(map(lambda x: ((x-m)/s)**3, lista)))Julia :
As = n / ((n-1) * (n-2)) * sum(((valor .- m) ./ s).^3)Esta é a fórmula que atualmente é utilizada no Excel / Calc, onde a assimetria é encontrada com a função = DISTORÇÃO(inicial, final)
Libs:
Exemplos
Python
dicio = {5:1, 6:7, 7:10, 8:10, 9:2, 10:2, 11:1}
lista = list(k for k, v in dicio.items() for _ in range(v))
m = sum(lista) / len(lista)
n = len(lista)
s = sum(list(map(lambda x: ((x - m)**2) / (n-1), lista)))**0.5
As = (n / ((n-1)*(n-2))) * sum(list(map(lambda x: ((x-m)/s)**3, lista)))
print(As)Julia
dicio = Dict(5=>1, 6=>7, 7=>10, 8=>10, 9=>2, 10=>2, 11=>1)
valor = [k for (k,v) in dicio for _ in 1:v]
n = length(valor)
m = sum(valor) / n
s = (sum((valor .- m).^2) / (n-1))^0.5
As = n / ((n-1) * (n-2)) * sum(((valor .- m) ./ s).^3)
Deixe um comentário